“What is domain testing?”
Another good question on Quora. Answering: What is domain testing?
*****
All terms originate somewhere else, by analogy. Here’s the origin for “domain”.
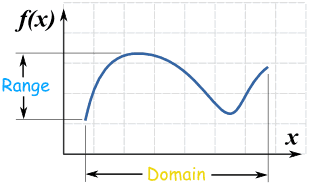
Image source: Domain of a function
- Domain is all possible inputs to the function
- Range is all possible outputs of the function
*****
At the fundamental level, everything is data in computers. Even machine code instructions are the data interpreted and executed by the processor.
At higher abstraction levels, code modules are also called functions, and they have input and output data. An idealized model looks something like that one below (source: Black box - Wikipedia).

But in reality, functions also often process data that weren’t passed to them, whether it’s internal variables, properties of the class, or some global data (using global variables is generally a bad - i.e. risky - practice). Furthermore, our system under test is a conglomerate of functions. So more realistic model would look something like below (source: Cem Kaner’s materials on software testing, Cem Kaner, J.D., Ph.D.).
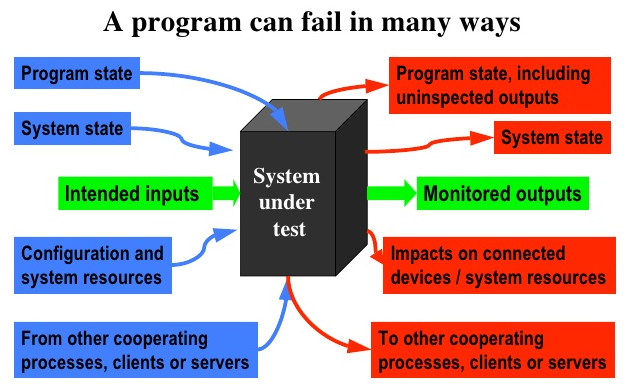
So domain testing is essentially about testing of data processing in the program.
In a shallow approach this testing indeed focuses only on inputs. But think: one function’s output is another function’s input.
Therefore, good domain testing strategy takes all data into consideration.
“All” is quite hard to track and handle, so for myself I use “Data SIFON” acronym, mind map below.
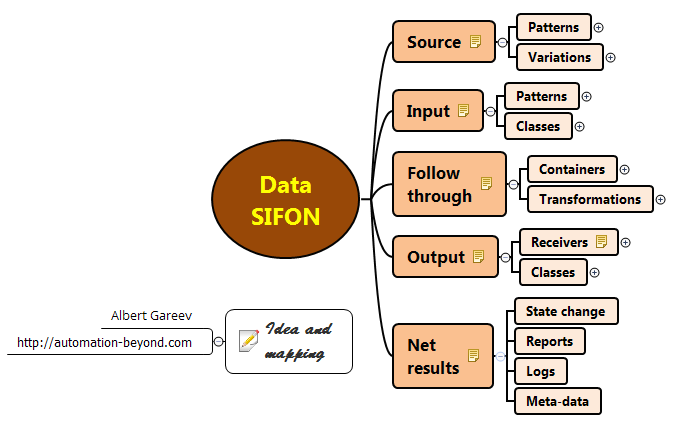
Full description pending publication in my blog or in a dedicated Quora answer. Some details for input aspect below.
Input - categories.
- Input patterns
- Explicit input by human operator
- Implicit input
- Defaulted input
- Input from non-humans
- Integration points with other programs (API, etc)
- Input or data change by internal modules of the product
- Classes of input
- Accepted
- Rejected
- Interrupted
- Failed
- Reverted
*****
Examples
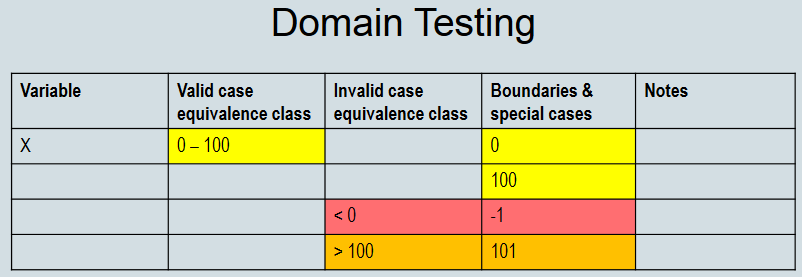
Source: Cem Kaner on Domain Testing - Online reference.
I find classic domain testing rather “academical”, with a lot of thought given to analysis and preparation of test cases. It’s perfectly fine and practical with a classic waterfall development approach when it takes weeks or even months before you get to see the program.
For quite a while now I’ve been in fast-paced development shops so I combine analysis with exploration. Sometimes, even design, because a table or a diagram built together with programmers helps us to have shared understanding right from the start and it helps preventing coding errors.
I also do domain-range analysis in the context of the actual program. Let’s say the example above is for Transaction Amount in an online banking system.
Applying Follow Through from the SIFON heuristic, I identify a number of data containers relevant to the data I want to test.
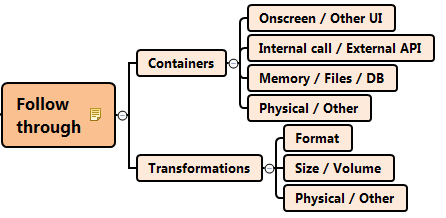
- Input box in the GUI form
- XML envelope of the submitted form
- Field(s) in the database
That’s a very minimum, assuming that I don’t have any access to internal code modules.
But there’s more! Let’s call out a few more examples.
- All features that display transaction amount
- Confirmation screen
- View Transactions feature
- All features that use transaction amount
- Daily maximum feature
- Account balance feature
Each of these functions utilizes one or few variables, that is - containers, to store and transport our data in question - Transaction Amount. Each of them may mishandle it.
In different situations I’d target certain or all of them, trying different tricks.
For example, testing extreme boundaries at the input box level I’d try samples like these.
- Type the highest number possible. Example: 9999999999999999999999999
99999999999999 - Paste the highest number possible.
- Using Firebug or other tool modify the input box, remove max length attribute. Then submit the highest possible number.
- Use scientific notation of a really big number. Example: 99E+99.
The truth is, before reaching the actual function that would do some computation, our data will “travel” in a number of “containers” (variables) each of them may have a problem of some kind.
- For example, program relying only on a client-side validation may erroneously accept samples (3) and (4).
- On the other hand, JavaScript by default accepts scientific notation of numbers, so if a program relies on the max length of the string as a boundary limit, there’s a good chance exploding functions down the “pipe”.
Speaking of output, I want to consider the “end points”.
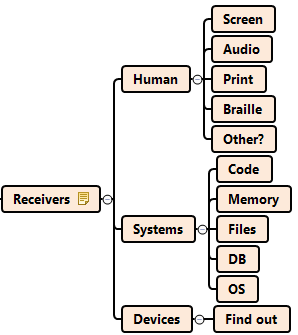
Mind that what is appropriate format or length in one program might be unsupported in another one. Furthermore, people perceive and process data way differently than programs, and even than each other. For example, a string like “SF235547U4GSERYE5677G34” as a transaction confirmation code is virtually useless for a blind person using Braille device or a Screen Reader program.
Conclusion
Finally, it begs the question: “..but there are millions of tests to run, what do I do?!”
And yes, no matter how we categorize our data samples, they’re just samples. Programs can surprise us in many ways.
This is why testing has tactical and strategic aspects.
- Techniques, like domain testing, help us with tactical questions: what tests to perform, what data to use, and so on.
- Techniques, like risk analysis, help us with strategic questions: what functionality or area to test, to what extent, when to stop / pause, and so on.
And we do it in collaboration with the team, that gives us critical input for both tactics and strategy.
Education
As everything in testing, best learning happens through practice. And best practicing is with a dedicated group led by skilled facilitators.
Association for Software Testing provides very affordable online AST-BBST Courses of high quality. They include Test Design course which covers Domain Testing techniques.
If you like to read alone, I recommend very solid Domain Testing Workbook by Cem Kaner and co-authors.
You can also ask Weekend Testing facilitators for a practice session on this or other testing subject.

One response to "“What is domain testing?”"
In software testing industry, in lemon language domain testing is also referred to branch or department or horizontal withing testing such as Banking domain, Telecom domain, Healthcare, Logistics domain.