Hidden Parts of the Performance Equation
This article was published on StickyMinds –
“Hidden Parts of the Performance Equation”, April, 2016.
The Performance Equation
Many teams decide to put together a “test bed” of servers and network infrastructure, develop some scripts simulating user requests, run the whole thing against the application, and see if they can satisfy the business requirements. And to make sure they have extra capacity, they double the number of transactions.
But this approach only seems to be working sometimes, meaning it’s failing the other times. And explaining why it works or fails is equally hard.
Let’s take a closer look at the parts constituting the “performance equation”.
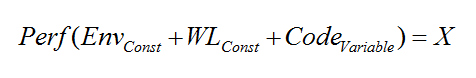
Where
- “Env” stands for Test Environment (network, switches, load balancers, servers, database, and platform software);
- “WL” stands for Workload scripts simulating user activity;
- “Code” stands for the Application code, including both in-house components and third-party libraries;
- And “X” is the set of performance characteristics (response time, throughput, etc.).
Environment
Hardware and software of testing environment have multi-faceted impact on the application’s performance. The typical “challenge fork” is that less powerful than production environment might be a cause for many unrealistic faults while more powerful than production environment will mask the real performance problems. It also might be financially challenging to replicate production environment so a “closest” available environment is used for performance testing. Often that might be a UAT or Pre-Production environment.
While risks of testing on significantly different hardware are readily seen, other differences might be not so obvious and remain not considered. Server settings, memory allocation, process priorities are the first to look at. Application settings may also result in performance variation. For example, debugging/logging levels may significantly change the frequency and volume of file operations.
Database structure and complexity of the contents may have a significant performance impact on functions like search and reporting. To address that risk, often a masked copy of production database is used.
It may take a few rounds of testing to uncover and tune out hidden factors of the environment component.
Workload Models
Workload models are often based on SLAs (Service Level Agreement) and business requirements. Some common examples include required number of transactions, number of concurrent users, and response times. A typical requirement might look like the following:
- Allow concurrent work of 10% of the total user base of 2,500 accounts;
- Support performing 2,500 transactions per hour;
- Page loading time should be no longer than 5-10 seconds;
- The system should stay up for a period of 8 hours.
Such requirements may seem very straightforward and so might be our workload models. For example, based on the requirements given above, one may need to simulate 250 concurrent users doing ten transactions per hour each, for eight hours. While doing so, also measure page loading time. And yes, to test the extra capacity let’s do twenty transactions per hour, or one every three minutes.
Are we missing something with this straight model?
To gain another perspective let’s look at the application traffic as a road traffic. A 100 meters long segment of a road can be concurrently occupied by 10 or more vehicles. But notice the difference in speed when there’s just a few of them or when they’re going bumper to bumper. Also notice that simultaneously on any given section there might be only as many cars as lanes. And if number of lanes would vary it’s the sections with least number of simultaneously bypassing cars that will greatly affect the speed of the traffic.

(Image credit: Metrolinx/Viva Toronto)
You probably see where this is going. Distributing the number of transactions evenly through a period of time takes into account concurrency of users but not simultaneously happening transactions. While one may argue that it’s unlikely that all 250 users will simultaneously press “Submit” what are the chances that ten would do so? Or even three? And this is where we most likely may encounter a “bottleneck”.
And what about the total number of concurrent users? Most of load testing tools and services have “charge per number of virtual users” pricing model. Many companies don’t own a license for 250 virtual users. A typical workaround used is to double or triple the speed of scripts to make up for the number of transactions. While it’s mathematically correct, this approach doesn’t take into account that number of user sessions has non-linear effects on the software system. Each user session requires allocation of resources (in application’s memory, on server, and in database), and resource management has a performance tax. Thus running the scripts three times faster doesn’t really make up for the equivalent number of users.
Code
If we assume that in our performance equation the code part is the only variable then any performance change should mean that the latest code drop has something to do with it.
Some code changes may indeed have a dramatic performance impact. But very often small changes here and there accumulate for some time before performance problems become apparent. Unless you have a trending graph of performance benchmarks for each build any slow decline might be hard to notice.
Even though testing may reveal performance degradation resolving the problem is challenged by an absence of a single root cause.
(Image credit: ASR’s Root Cause Analysis Questionnaire)
Constant workload models are intended to establish a baseline for tracking. They execute the same scripts in the same load fashion. But that also means exercising the same application functions in the same way. Real users perform variety of operations. Along with transaction booking they may search, edit, remove data, and run reports. All those functionalities may stay “outside” of the generated load but have a real impact on performance if used in parallel with it.
And there are newly deployed features in the same functions. For example, account lookup, editing of shopping cart, and so on. If the scripts submit transactions in the same fashion they’re not addressing many of code changes.
Conclusion
Testing – all testing – is a blend of activities: learning, modeling, experimenting, and investigating. Testing is much more about discovery of systems’ behaviors than verification of few samples of expected behavior. Load and performance testing is no exception. Only through iterations of trial and error we can learn about the system and develop useful workload models.
Look for hidden parts in your performance equation especially if it looks simple to solve.
